% ./ccfs path-to-encrypted-files name
Passphrase:
path-to-encrypted-files is the path to a directory
under which you want to store encrypted files. Once CCFS is running
you will be able to access unencrypted versions of the files under
/classfs/name. The minute you kill CCFS, however,
the contents of the files will be inaccessible to someone who doesn't
know the correct passphrase to restart CCFS. By the end of the labs,
your file system will work something like this:
% mkdir /shome/cl2/scratch/myname % ./ccfs /shome/cl2/scratch/myname myname Passphrase: ^Z Suspended % bg [1] ./ccfs /shome/cl2/scratch/myname myname & % touch /classfs/myname/test % echo hi > /classfs/myname/there % cp /etc/termcap /classfs/myname/ % ls -al /classfs/myname/ total 732 drwxr-xr-x 2 dm dm 512 Sep 23 21:38 . dr-x------ 4 dm sfs 512 Sep 23 21:37 .. -r--r--r-- 1 dm dm 732361 Sep 23 21:38 termcap -rw-r--r-- 1 dm dm 0 Sep 23 21:37 test -rw-r--r-- 1 dm dm 3 Sep 23 21:37 there % ls -al /shome/cl2/scratch/myname total 735 drwxr-xr-x 2 dm dm 512 Sep 23 21:38 . drwxr-xr-x 31 dm dm 4096 Sep 23 18:32 .. -rw-r--r-- 1 dm dm 16 Sep 23 21:37 8gM7Ga4VrGrDJZjTa0Ruzg -rw-r--r-- 1 dm dm 531 Sep 23 21:37 dWbFGNqKIUCB-dw0w10rRg -r--r--r-- 1 dm dm 732889 Sep 23 21:38 ml0WK4ekrOXRPOG0CvCVZQ % kill %./ccfs [1] Terminated ./ccfs /shome/cl2/scratch/myname myname % ls -al /classfs/myname/ ls: /classfs/myname: No such file or directory %Not only are the file names on disk unintelligible, but the file contents, too. Thus, even someone who breaks into the file server will not be able to read your files without knowing the secret passphrase.
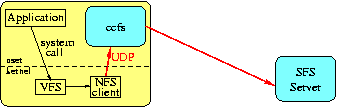
You will begin this project with a ``dumb,'' ~100-line file system that does nothing but relay NFS calls. You will build CCFS by progressively modifying this dumb file system until it encrypts all file contents and file names.
In order to build CCFS, you will make use of the classfs framework. Classfs
contains a daemon, classfsd, a library,
libclassfs.a, and a header file, classfscli.h.
The principal purpose of the library and associated header are to
communicate with classfsd and the remote SFS server when
initially setting things up. classfsd is already
installed and running on the class machines. The library is in
~class/src/classfs.
The classfsd daemon serves two functions. First, it
handles the nasty and unportable details of creating NFS loopback
mounts. Second, it will clean up the mess if your CCFS implementation
crashes. classfsd is only active when you are first
starting up or after CCFS exits or crashes. Otherwise, your CCFS
implementation will be speaking NFS directly to the kernel.
% ssh -t class-serv.scs.stanford.edu sfskey register sfskey: creating directory /home/fs/yourname/.sfs Registering new user yourname@class-serv.scs.stanford.edu. Creating new key for yourname@class-serv.scs.stanford.edu. Key Name: yourname@class-serv.scs.stanford.edu Enter passprase: type a passphrase Again: type it again sfskey needs secret bits with which to seed the random number generator. Please type some random or unguessable text until you hear a beep: DONE UNIX password: type your password here Connection to class-serv closed. %It may take several minutes for your public key to propagete to all the class machines, so run this command now before reading the rest of the lab.
Once you are registered with the SFS server, you must run an sfsagent
process on any client machine from which you wish to access an SFS
server. You have been accessing files on the class machines under
/home through NFS. However, once you have run an
sfsagent, you can access the same files through SFS under
/shome. This includes both your home directory
(/shome/cs2/yourname) and the scratch directories under
/shome/clN. When you are done, before logging out, you
should kill your agent with the sfskey kill command.
For example:
% sfsagent Passphrase for /home/fs/yourname/.sfs/identity: type your passphrase % cd /shome/fs/yourname % ls -al drwxr-xr-x 8 student class 512 Sep 23 22:55 . drwxr-xr-x 15 root wheel 512 Sep 10 18:21 .. -rw------- 1 student class 811 Sep 23 22:50 .Xauthority -rw------- 1 student class 3418 Sep 6 11:41 .Xdefaults -rw-r--r-- 1 student class 2841 Sep 6 11:42 .cshrc -rw------- 1 student class 6625 Jan 17 2001 .emacs ... %And when finally logging out:
% sfskey kill
sfsagent: EOF from sfscd
sfsagent: exiting
%
~class/src/ccfs.tar.gz. The
setup procedure is similar to the previous lab, except that you must
additionally give ./configure the argument
--with-classfs=/home/cs2/class/src/classfs:
% cd % tar xzf ~class/src/ccfs.tar.gz % cd ccfs % sh ./setup + chmod +x setup + libtoolize ... + set +x *** * * * * * * * * * * * * * * * * *** *** setup succeeded *** *** * * * * * * * * * * * * * * * * *** % mkdir -p /home/cl3/scratch/yourname/ccfs % pushd /home/cl3/scratch/yourname/ccfs /home/c3/scratch/yourname ~/ccfs % setenv DEBUG -g % =1/configure --with-classfs=/home/cs2/class/src/classfs --with-sfs=/home/cs2/class/src/sfs1 creating cache ./config.cache checking for a BSD compatible install... /usr/bin/install -c checking whether build environment is sane... yes checking whether make sets ${MAKE}... yes checking for working aclocal... found checking for working autoconf... found checking for working automake... found checking for working autoheader... found checking for working makeinfo... found checking host system type... i386-unknown-openbsd2.9 ... updating cache ./config.cache creating ./config.status creating Makefile creating config.h % gmake ...(If you are using classN, then make your build directory on /home/clN rather than /home/cl3.)
% mkdir /shome/cl2/scratch/myname % ./ccfs /shome/cl2/scratch/myname myname ^Z Suspended % bg [1] ./ccfs /shome/cl2/scratch/myname myname & %Now
/classfs/myname and
/shome/cl2/scratch/myname will appear to be the same
directory, except that /classfs/myname will be going
through your software.
NOTE: You cannot access an SFS server from a
client on the same machine. Because of the NFS loopback server
deadlock issues we discussed in class, SFS will not connect to a
client on the same machine. If, for instance, you try to access
/shome/cl2 on class2, you will get a ``Resource
deadlock avoided'' or ``not an SFS file system''
error.
When you kill CCFS, classfsd will attempt to unmount the
file system. It will be unable to do so if any of your shells still
has /classfs/myname as a working directory. Thus, make
sure to cd / after killing CCFS. If you forget to leave
a directory after killing CCFS, and you try to restart CCFS using the
same second argument (name under /classfs), CCFS will
give you the error File exists.
One final word about
After setting up CCFS to trace NFS traffic, run the following commands:
For encrypting and decrypting data, you will be using the Rijndael
(AES) algorithm. The implementation you will be using is described below. One of the complications of encrypting file data
is that AES operates on blocks of 16 bytes. Thus, all read and write
operations must be in aligned multiples of 16 bytes. Furthermore,
files with sizes not a multiple of 16 bytes will have to be padded
slightly. Before adding encryption to CCFS, therefore, you will first
modify the software to deal with file padding and to read and write
multiples of 16 bytes.
Though you may be adding a few bytes to the ends of files, you would
like file sizes to appear correct to the user. It is easy to do this
if you observe the following rule: Add 16 bytes to the size of a file
if and only if its size is not a multiple of 16 bytes. Thus, a
16-byte plaintext file will result in a 16-byte ciphertext file, but a
17-byte plaintext file will result in a 33 byte ciphertext file.
Given this scheme, ciphertext file sizes can easily be adjusted in
file attributes to contain the size of plaintext files. [If
(size>16) and (size&15) then size-=16.]
Before adding encryption, then, you will need to modify the following
RPCs:
For writes the do end on a multiple of 16 bytes, another issue
comes up. If a file's previous length was just under its current
length, you may need to truncate the file. For example, a 15 byte
plaintext file will result in a 31 byte ciphertext file. If you
append one byte to this file, the ciphertext file will still be 31
bytes, when in fact it should be 16.
You can correct this problem by checking the attributes of a file
after a write. For your convenience,
Note: Don't write 20 different functions to do this, one for each NFS
RPC. See the
You can ensure that identical 16-byte regions are encrypted
differently by throwing the position into the equation. Let E(B)
represent the encryption of 16-byte block B. (Of course, E requires
an encryption key not shown in this notation. Just think of E as a
method of an object that contains the key.) When transforming the
plaintext data block P at offset pos to ciphertext block C,
you should calculate C = E(P XOR E(pos,0)). In other words,
pad the position pos to 16 bytes with 0s, and encrypt it to
generate 16 bytes of random looking data. Then XOR this data,
byte-by-byte, with the plaintext before encrypting. If D is the
decryption function, then to decrypt you can simply compute P = D(C)
XOR E(pos,0).
Note: Ordinarily, when one creates a sparse file (by extending the
file with ftruncate or by writing far beyond the end of the file),
unwritten portions of the file contain zeros. It is okay for CCFS not
to emulate this behavior, but to contain garbage (the result of
``decrypting'' zeros) in sparse regions of files.
Fortunately, most NFS client implementations only generate concurrent
writes to the same files when those writes are for aligned buffers.
Thus, you do not need to solve this problem in this part of the lab.
Another potential problem might occur if the client issued reads
beyond the end of the file. For example, suppose you have a 17 byte
plaintext file, and thus a 33 byte ciphertext file. Now suppose the
client issued a read at offset 0 with count 32 bytes. According to
the algorithm given for the lab, CCFS would pass the request straight
through and get 32 bytes of data back without the eof flag set.
You can test for reads beyond the end of file using the attributes in
the reply of the read. However, most NFS client implementations will
not return data for read system calls that extend beyond the
Note that the compilation is somewhat lengthy. You probably don't
want to run it with
For extra credit, modify CCFS so that the first time you mount a
ciphertext directory, it prompts you for the passphrase twice,
aborting if the two passphrases do not match. On subsequent
invocations, CCFS should refuse to mount a particular directory if you
don't type the correct passphrase (as opposed to running, but
encrypting everything with the wrong key).
Hint: You may pick a ``reserved'' file name that you assume no
application will access. For example, the file name
NOTE: If you cut out all the entries in a READDIR or READDIRPLUS
reply (for instance, because they are all hidden file names), you must
either set eof or issue a new RPC starting at the cookie in the last
entry you cut.
Include in the handin directory a short text file called
There are several complications to encrypting file names. First, AES
works on blocks of 16 bytes. File names must therefore be padded to a
multiple of 16 bytes. This is okay--since file names cannot contain
0-valued bytes, you can pad file names with zeros, and then when
decrypting determine the length by finding the first zero (if any).
Conversely, since file names cannot contain 0-valued bytes, you must
ensure that the result of encrypting a file name does not produce a
string containing zero bytes. Simply running a 16-byte block of an
ASCII file name through the AES encryption algorithm produces
random-looking binary data, which risks containing a zero byte. Even
if the binary data does not contain a zero byte, it might contain
'
Another issue is that for file names longer than 16 bytes, you would
like to conceal any 16-byte plaintext blocks that are repeated.
Otherwise, people may deduce things they shouldn't from your
ciphertext file names. For example, suppose you have a directory
containing four files, named
It is a general problem when using block ciphers like AES that you
would like to conceal any repetition of 16-byte regions of plaintext.
In the case of individual files, you helped alleviate this problem by
XORing in an encryption of the 16-byte block position. File
encryption is somewhat special in that one needs to support random
access to file contents. For encrypting a stream of bytes that does
not require random access, people often employ a technique known as
cipher block chaining (CBC). To encrypt in CBC mode, one XORs
each plaintext block with the encryption of the previous block before
encrypting, as shown here:
If the plaintext blocks are m1, m2, ..., and the
ciphertext blocks c1, c2, ..., then encryption
and decryption in CBC mode are performed as follows:
When encrypting links, you would like two symbolic links to look
different even if they are pointing to the same destination. This can
easily be achieved by choosing a random initialization vector and
prepending it to the encrypted link contents. Thus, the process of
encrypting a link will have the following steps (where ## denotes
concatenation):
Unlike symbolic link contents, file names in directories cannot be
randomized in CCFS. If a user creates a file, and later looks up the
file by name, the same plaintext file name must always encrypt to the
same ciphertext name so that you look up the same file. However, you
would still like to conceal any repetition of 16-byte blocks in
plaintext file names. You can do this if every byte of an encrypted
file name depends on every byte of the plaintext file name.
Encrypting file names in CBC mode would ensure that a plaintext
block's encryption depended on all previous plaintext blocks.
However, in the case of file names, we would also like a block's
encryption to depend on any subsequent blocks. You can achieve this
by encrypting file names twice in CBC mode, once forwards and once
backwards. As an optimization, the last block does not need to be
encrypted twice. Thus, file names of 16 bytes or less will only
require one encryption. To encrypt a file name with blocks
n1, n2, ..., nk you compute the
encryption c1, c2, ..., ck in terms
of intermediary values c'i as follows:
File names occur in the arguments of a number of different NFS calls,
but always as part of a
File names appear in the replies to two NFS RPCs, NFSPROC3_READDIR and
NFSPROC3_READDIRPLUS. You must decrypt all file names in the replies
to these RPCs. You can do this by just manually traversing the linked
lists of
NOTE: For obvious reasons, do not encrypt or decrypt the file
names ``
Hint: If you implemented the last extra-credit, you already store some
state to verify a mount point's password. You can store additional
state to help with the encryption and decryption of file names.
Include in the handin directory a short text file called
In this final part of the lab, you will introduce a per-file
initialization vector that ensures two files with the same contents do
not produce the same encryption. Whenever a file is created, you will
chose a 64-bit initialization vector for the file. Recall that in
part B, you converted between a plaintext file block P at offset
pos and the corresponding a ciphertext block C with:
The remaining question is where to store the initialization vector.
The simplest technique is simply to store the initialization vector in
the file itself, at the beginning of the file. You can simply add 8
bytes to the offsets of all READ and WRITE RPCs. Similarly, you must
subtract 8 from the
You will want to keep a cache of initialization vectors, to improve
performance. When you see a reference for a file handle not in the
cache, you should read the first 8 bytes of the file. (The file may
be zero length because of a crash. In this case, it would be elegant
to write a new IV, but for the purposes of this lab you may also just
return NFS3ERR_IO.)
In addition, you must store the initialization vector in a file when
the file is first created. The complication here is that in response
to non-exclusive opens (O_CREAT but not O_EXCL), clients may call
NFSPROC3_CREATE on files that already exist. With
You should employ two techniques to avoid overwriting initialization
vectors. First, if a file's length is non-zero, do not write the IV.
Instead, read what has already been written to the file. Second, use
a deterministic 64-bit hash of the NFS file handle as an
initialization vector (for instance, the first 64-bits of a SHA-1 hash
of the handle). NFS file handles rarely change (usually only when the
server is restored from a backup tape or the server's software is
upgraded). Thus, even if two clients accidentally write the same IV,
chances are overwhelming that they will chose the same value. (NOTE:
As an alternative to these approaches, you might instead implement
Include in the handin directory a short text file called
As an added feature, on successful NFSPROC3_READ and NFSPROC3_WRITE
calls,
To define a new type of data structure traversal, you must create some
new type
Rather than get into the details of how C++ function templates work,
this is best illustrated by an example. Suppose you wish to modify
CCFS to make all file names lower-case, regardless of the name of the
file accessed by the user. In other words, if you create or read a
file called ``
For actually encrypting and decrypting file data, you
will use the AES
block cipher. AES is a 128-bit block cipher. It supports two
operations--encryption, and decryption. Encryption transforms 16
bytes (128 bits) of plaintext data into 16 bytes of
ciphertext data using a secret key. Someone who does not know
the secret key cannot recover the plaintext from the ciphertext. The
decryption algorithm, given knowledge of the secret key, transforms
ciphertext into plaintext.
The libraries you are using define a class called
For someone who steals the file of password hashes, there is no
know way of recovering passwords more efficient than guessing
passwords and verifying the guesses. (Of course, the fact that users
often choose easily-guessed passwords is a problem.)
Collision-resistant functions have many uses, stemming from the fact
that the short output value effectively uniquely specifies an
arbitrary length input. One cannot recover the input from the output,
but given the input, one can verify that it does, indeed, match the
output. One might, for instance, implement a web cache in which
contents is indexed by a SHA-1 hash of the URL. Having fixed-length
names for stored content would simplify the implementation.
classfsd: Because of the risk of
deadlock with NFS loopback mounts, classfsd takes over the server UDP socket
and attempts to unmount the file system. This should ordinarily not
cause you any trouble, but if you leave CCFS stopped under the
debugger for 10 minutes, your file system will get unmounted.
Tracing RPCs
Once you've gotten the skeletal CCFS running, try the following
command in one window, while browsing /classfs/myname in
a different window:
% env ASRV_TRACE=10 ./ccfs /shome/cl2/scratch/myname myname
This command prints a complete trace of all NFS requests received by
CCFS. (Large structures may be truncated; if this is ever a problem,
try higher values than 10.) Similarly, setting ACLNT_TRACE instead of
ASRV_TRACE shows a trace of all the NFS requests CCFS sends to the
remote SFS server. Tracing RPCs can be invaluable in debugging
strange behavior of your cryptographic file system--you can usually
track the problem to a single RPC and then see why your code is
misbehaving in that case.
Now redirect the tracing output to a file:
% env ASRV_TRACE=10 ./ccfs /shome/cl2/scratch/myname myname >& nfs.trace
(Note, you must use >& rather than just
> because the tracing goes to standard error. If you
use a Bourne-like shell instead of the default tcsh, you might need to
use 2> instead of >&.)
% cd /classfs/myname
% rm junk
rm: junk: No such file or directory
% echo hello > junk
% cat junk
hello
% cat junk
hello
%
Now stop CCFS, and look at the RPCs in the nfs.trace
file.
What to hand in
Hand in a copy of the nfs.trace file, which you have
annotated to show which RPCs correspond to which of the commands you
ran. At the end, briefly explain any difference between the RPCs
caused by the two cat commands. As usual, you should copy this
nfs.trace to ~class/handin/lab2a/`logname`/.
Part B -- Encrypting file contents
In this part, you will modify CCFS to encrypt all file contents
written to the server and decrypt all contents read from the server.
You will primarily do this by special-casing the NFSPROC3_READ and
NFSPROC3_WRITE RPCs, but you will also need to change handling of
NFSPROC3_SETATTR. Finally, in all NFS RPCs you will need to adjust
returned file attributes slightly.
Once you have modified CCFS to read and write data in aligned
multiples of 16-bytes, you are ready to begin encrypting and
decrypting file contents. Upon startup, CCFS should get a passphrase
from the user and initialize an libclassfs always
guarantees that the attributes of a file are present after an
NFSPROC3_READ or NFSPROC3_WRITE RPC. Thus, the
resok->file_wcc.after field of the write3res
structure will tell you the size of the file. If the end of your
write was at offset pos, pos is a multiple of 16, and
the current file size lies between pos and
pos+16, then you should truncate the file to pos bytes
with an NFSPROC3_SETATTR call. To avoid race conditions, you should
make the SETATTR call guarded using the ctime of the file
in the attributes from which you got the length.
type field of
the fattr3 structure is NF3REG), you must
adjust the file length if it is not a multiple of 16 bytes. If for
some reason a ciphertext file is less than 16 bytes, just report the
length of the plaintext file as 0 (no negative sizes, please). For
replies that contain wcc_data, make sure the pre-operation size is
also adjusted (or, if you don't know the type of the file, remove the
wcc_attr from the reply).
nfs3_getattrinfo function
below.
aes object with this
passphrase. One possible approach to encrypting files is simply to
encrypt every 16-byte region with the aes object.
However, then if two 16-byte regions of a plaintext file contain the
same data, the encrypted file will contain the same ciphertext. For
better security, such patterns should be hidden from people who have
access to the ciphertext file.
Assumptions about NFS client behavior
As currently described, CCFS could potentially suffer race conditions
if it receives concurrent writes to the same file. For example,
suppose a file is initially zero-length, and the NFS client issues two
writes, one for 8K-1 bytes at offset 0, the other for 8K bytes at
offset 8K. The NFS RPCs might proceed as follows:
Here Write1' will clobber the first 15 bytes of data written by
Write2. The correct way to protect against this would be to keep
track of outstanding WRITE RPCs on a particular file. This will be
easier to do once you complete part D of the lab. A related problem
would happen if the client issued two writes to the same 16-byte
region (for instance writing byte 1 and byte 2 of the file in
different RPCs).
NFS Client
CCFS
SFS Server
Write1 (off=0, count=8K-1) Write2 (off=8K, count=8K) Read1 (off=0, count=8K+15) Write2' (off=8K, count=8K) Read1-reply (EOF) Write2'-reply Write1' (off=0, count=8K+15) Write2-reply Write1'-reply Write1-reply size field of fattr3 structures. Thus, you
don't need to worry about this situation if you adjust file sizes
properly.
Testing
To test your file system, you should make sure it is
able to compile the gzip compression program. There is a script, ~class/bin/test-fs, which
compiles gzip in the current working directory. (It uses a tiny
utility called microtime
to print out timestamps, but for the purposes of this assignment only
correctness matters.) Your test should look something like this:
% mkdir /shome/cl2/scratch/myname
% ./ccfs /shome/cl2/scratch/myname test
Passphrase:
^Z
Suspended
% bg
[1] ./ccfs /shome/cl2/scratch/myname test &
% cd /classfs/test
% test-fs
DIRECTORY: /classfs/test
TIME: START == Fri Jan 20 22:12:11.838528 PST 2006
tar xzf /home/cs2/class/src/gzip-1.2.4a.tar.gz
0m0.82s real 0m0.01s user 0m0.00s system
TIME: UNTARRED == Fri Jan 20 22:12:12.666431 PST 2006
env CFLAGS= ./configure
checking for gcc
...
creating Makefile
0m1.31s real 0m0.14s user 0m0.15s system
TIME: CONFIGURED == Fri Jan 20 22:12:13.980164 PST 2006
gmake
gcc -c -DASMV -DSTDC_HEADERS=1 -DHAVE_UNISTD_H=1 -DDIRENT=1 gzip.c
...
ln gzip gunzip
ln gzip gzcat
0m1.38s real 0m0.48s user 0m0.14s system
TIME: COMPILED == Fri Jan 20 22:12:15.363102 PST 2006
rm -rf gzip-1.2.4a
0m0.25s real 0m0.00s user 0m0.00s system
TIME: END == Fri Jan 20 22:12:15.621950 PST 2006
% cd /
% kill %./ccfs
[1] Terminated ./ccfs /shome/cl2/scratch/myname myname
%
If there is a compilation error, and you don't get to the end of the
script (the rm -rf command), then your file system is
doing something wrong. This will most likely manifest itself as
./configure failing to run, or the compilation failing.
dmalloc -i 1, as the test will take
too long. Just plain dmalloc high -i 0, or else -i
1000 should be fine.
What to hand in
As usual, make a tar.gz file with the command make
distcheck. Copy the ccfs-0.0.tar.gz and a
typescript file of your testing to
~class/handin/lab2b/username.
Extra credit
If you forget the passphrase you type to CCFS, you will lose all your
files. There is no way to recover them. Ordinarily, this shouldn't
be a problem. People using a tool like CCFS must accept that they
cannot forget their passphrase. However, there is one slightly risky
situation--what if you mistype your passphrase the first time you are
creating a directory. On subsequent accesses, you will remember the
password you wanted to type, but may not easily be able to figure out
what you actually typed.
".SFS
\177KEY". (As a C-string, the '\177' is a delete
character. Applications typically don't put spaces and deletes in
file names.) You may store something in that file that helps you
verify the key, or the file could be a symbolic link. However, make
sure the file name doesn't show up in plaintext directory listings or
it might confuse users.
extra-credit with a description of the exact technique
you used to implement this feature.
Part C -- Encrypting file names and symbolic links
While CCFS currently encrypts file contents, you can still learn quite
a bit about the contents of a directory tree from the file names. In
this part of the lab, therefore, you will extend CCFS to encrypt file
names and symbolic links.
/' characters, which are also illegal, or else control
characters or other octets that would not display well on people's
terminals. Thus, you should transform encrypted file names back to
ASCII test using the armor64A
function (for which you must include "serial.h").
a, b,
17char-filename-a, and 17char-filename-b.
If you simply encrypt block-by-block, an attacker will know the
following:
If the attacker happened to know you were running some application
that produced files called 17char-filename-a, ..., he or
she would then know that you also had files called a,
....
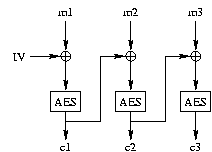
ci = E(mi XOR ci-1)
The first plaintext block is XORed with an initialization vector, or
IV (which you can think of as c0, since there is no
m0). The IV can be publicly known. It is often just 0,
unless the same key will be used to encrypt multiple streams, in which
case each stream must use a different IV.
mi = D(ci) XOR ci-1
Encrypting symbolic links
You should start by encrypting the contents of symbolic links, as this
is simpler that most other occurrences of file names. You will modify
the NFSPROC3_SYMLINK and NFSPROC3_READLINK RPCs to encrypt and decrypt
the contents of symbolic links, respectively.
Decryption follows the reverse process. In implementing this, you may
find some of the string functions
below useful.
Encrypting file names
c'0 = 0
c'i = E(mi XOR c'i-1)
(for 1<=i<=k)
ck = c'k
ci = E(c'i XOR c'i+1)
(for 1<=i<k)
diropargs3 structure. The nfs3_traverse_arg function template
described below can help you process all diropargs3
structures without special-casing each NFS call. Thus, you need only
write a single function to encrypt the file name in a
diropargs3 structure.
entry3 and entry3plus data
structures. (It's not worth using nfs3_traverse_res,
since each data structure appears in only one return type.)
.'' and ``..''!
What to hand in
As usual, make a tar.gz file with the command make
distcheck. Copy the ccfs-0.0.tar.gz and a
typescript file of your testing (including an invocation
of test-fs) to
~class/handin/lab2c/username.
Extra credit
People tend to reuse passwords. It would be nice if when a user
creates two, separate encrypted directories but uses the same password
for both, file names nonetheless look different. For extra credit,
modify CCFS so that each time you create an encrypted mount point, the
same file names look different even if you choose the same password.
extra-credit with a description of the exact technique
you used to implement this feature.
Part D -- Initialization vectors
CCFS now encrypts both file names and file contents. However, if two
plaintext files contain the same 16-byte data block at the same
offset, the corresponding ciphertext blocks will also be identical.
This may reveal information it shouldn't about file system usage. For
example, the emacs text editor keeps backup copies of files
(``~ files''). By comparing a ciphertext file to its
backup one can tell at what offset a user started editing.
C = E(P XOR E(pos,0))
Now you will add the file's initialization vector to the equation:
P = D(C) XOR E(pos,0)
C = E(P XOR E(pos,IV))
P = D(C) XOR E(pos,IV)
size field of the fattr3
and wcc_attr structures of regular files before
performing the other length adjustments from part B.
how set to UNCHECKED, such CREATE RPCs will
succeed. You want to avoid at all cost overwriting the initialization
vector of a file, as you will turn the contents of the file to
garbage.
UNCHECKED CREATE RPCs in terms of GUARDED
ones.)
What to hand in
As usual, make a tar.gz file with the command make
distcheck. Copy the ccfs-0.0.tar.gz and a
typescript file of your testing (including an invocation
of test-fs) to
~class/handin/lab2d/username.
Extra credit
Add a per-directory initialization vector. In the extra credit for
Part C, you already made the same plaintext file names produce
different ciphertext names in different CCFS mountpoints. Extend this
mechanism so that even within a single CCFS mountpoint, files with the
same name in different directories have different encryptions.
extra-credit with a description of the exact technique
you used to implement this feature.
Useful references
In addition to the class references
page, you may find the following links useful:
~class/src/sfs1/svc/nfs3_prot.x --
NFS3 protocol spec in XDR format. (Note that this file is slightly
simplified from the RFC 1813 syntax, but generates the same wire
protocol.)
~class/src/classfs/classfscli.h --
Interface to libclassfs.
~class/src/sfs1/crypt/aes.h --
Interface to AES encryption code.
Useful classes and functions
Standard library
char *getpass(const char *prompt);
Displays prompt to the user and reads a password typed at
the terminal, turning off echo so that others cannot see the password
typed. The password is returned as a pointer to a nul-terminated C
string.
String functions
In addition to the discussion of str objects in Using TCP through sockets, you
may find the following useful:
str::str (const char *buf, size_t len);
Constructor for the str object type, that copies
len bytes at buf to create a string. You
must use this constructor when a string might contain zero-valued
bytes. An example usage:
aes fskey;
char buf[16];
...
fskey.encipher_bytes (buf);
str result = armor64A (str (buf, sizeof (buf)));
str substr (str s, size_t pos, size_t len);
Returns the substring of s starting at position
pos and extending len bytes. If
pos is greater than the length of the string, the empty
string is returned. If pos+len is greater
than the length of the string, the result will go to the end of the
string and be shorter than len bytes.
str substr (str s, size_t pos);
When called with only two arguments, returns the substring of
s starting at position pos and extending to
the end of s. If pos is greater than the
length of the string, the empty string is returned.
Data serialization
The following functions are defined in "serial.h":
void putint (void *dp, u_int32_t val);
void puthyper (void *dp, u_int64_t val);
The putint function puts the 32-bit integer value of
val into memory in big-endian order at location
dp. dp does not need to be aligned. The
bytes stored at dp will be the same on big- and
little-endian machines. puthyper is like
putint but puts a 64-bit value into 8 bytes of memory.
u_int32_t getint (const void *dp);
u_int64_t gethyper (const void *dp);
The getint and gethyper routines retrieve
values stored by putint and puthyper
respectively.
str armor64A (str bin);
Transforms a binary string containing arbitrary bytes to a longer,
base-64, printable ASCII string, suitable for use as a file name. You
will need to use this to transform binary encrypted file names, since
file names cannot contain the 0-valued byte (and it is generally not
advisable to embed control characters in file names).
str dearmor64A (str asc);
Inverts the armor64A function, or returns NULL if its
input is not the output of armor64A.
NFS-related functions
For the following functions, you need these includes:
#include "nfsserv.h"
#include "nfs3_nonnul.h"
#include "classfscli.h"
The skeleton CCFS code you will start with has a dispatch
function that takes an argument nfscall *nc. This
function gets called for every NFS3 RPC CCFS receives. The
nfscall object has the following methods (written here as
you would invoke these arguments on nfscall *nc):
CCFS also has a global object u_int32_t nc->proc ();
Returns the procedure number of the RPC (i.e.,
NFSPROC3_NULL, NFSPROC3_GETATTR, ...)
T *nc->Xtmpl getarg<T> ();
Returns the arguments to the RPC call. getarg is a C++
template function. Here T is the actual type of
the argument, as found at the bottom of nfs3_prot.x. You must supply the
type when you invoke the function. For example:
It is an error to ask for a type other than the argument for that
particular RPC call. If you compile with dmalloc, you will get a core
dump when asking for the incorrect argument type. Note
if (nc->proc == NFSPROC3_LOOKUP) {
diropargs3 *argp = nc->Xtmpl getarg<diropargs3> ();
// ...
}
Xtmpl is a macro that either expands to the keyword
template, or to nothing. This is required to work around bugs in
certain versions of g++.
void *nc->getvoidarg ();
getvoidarg returns a pointer to the RPC arguments, cast
to void *. You can call getvoidarg
regardless of the RPC procedure number--thus, it is useful in cases
where you wish to perform some action on calls of multiple RPC
procedures.
T *nc->Xtmpl getres<T> ();
getres returns a pointer to the appropriate RPC return
type for this RPC procedure. The object pointed to will automatically
be deallocated when you reply to the RPC. Strictly speaking, this
procedure is not necessary. You can just allocate the appropriate
return type for any given RPC call. However, it turns out to be handy
to have an object of the correct return type around, particularly if
it automatically gets deallocated when no longer needed.
void *nc->getvoidres ();
Returns a pointer to the same object as getres, but cast
to void *.
void nc->reply (void *res);
Replies to an NFS RPC. res is a pointer to the data
structure containing the results. For example, if you stored the
results in the structure you got from getres, you might
reply to an RPC with:
nc->reply (nc->getvoidres ());
void nc->error (nfsstat3);
Replies to an NFS3 RPC with a particular error code. The
error method automatically takes care of filling in the
rest of the reply based on the particular RPC you are replying to.
Any optional attributes in the error reply will be omitted. For
example, if, without worrying about what procedure has been called,
you wish to reject an NFS RPC with an ``access denied'' error, you can
write nc->error (NFS3ERR_ACCES);
void nc->reject (accept_stat);
The reject method rejects an NFS RPC with an RPC-level
error, rather than an NFS error. Ordinarily it is better to reject
NFS RPCs with NFS errors (the error method). However,
when relaying calls from an NFS client to an NFS server, RPC errors to
the server can be relayed back to the client. There is not a direct
mapping from the RPC type accept_stat to the
clnt_stat type returned by RPC client code. However, the
generic RPC error SYSTEM_ERR is a suitable value. The
skeletal CCFS code for this lab already returns a
SYSTEM_ERR in response to any RPC failures.
c of type
ptr<sfsuclnt>. This object is used to send NFS
RPCs to the remote SFS server that was specified on the command line.
For more information, see classfscli.h. The main method
you need to use is:
One often wants to perform some operation for a large number of
different NFS procedures. One possible approach is to demultiplex all
21 different NFS RPCs into different dispatch functions, and in each
function implement the functionality you want. This turns out to be
fairly painful in practice because you must write a large amount of
repetitive code. Several functions use C++ templates to save you from
having to do this.
void c->call (u_int32_t nfs_procno, void *argp, void *resp, aclnt_cb cb);
Sends an NFS call to the remote SFS server. nfs_procno
is the procedure number, argp a pointer to the arguments,
and resp a pointer to where the results should be stored.
cb is an ordinary RPC callback--it receives an argument
of type clnt_stat to indicate any RPC-level errors.
sfsuclnt::call guarantees the presence of the
file's attributes on return. (That is, if the
post_op_attr field of the result is not present upon
return, sfsuclnt::call will fetch the attributes for you
and put them in the read3resok or
write3resok structure.)
DUMBTRAVERSE (type)
template<class T> bool nfs3_traverse_arg (T &t,
u_int32_t proc, void *argp);
template<class T> bool nfs3_traverse_res (T &t,
u_int32_t proc, void *resp);
The nfs3_traverse_arg and nfs3_traverse_res
function templates allow you to traverse NFS argument and return types
for all 21 different NFS RPCs, and perform some operation on
particular structures found during the traversal. Because these are
function templates, and not functions, they can be instantiated
multiple times to generate different functions performing different
traversal operations on data structures. Each instantiation of a
traversal function is designated by a unique type T--the
type of the first argument to nfs3_traverse_arg or
nfs3_traverse_res.
T for this traversal. For any given type, the
macro DUMBTRAVERSE defines empty functions for all the
basic types encountered during traversal (such as int).
You will generally want to use DUMBTRAVERSE to do nothing
by default, but then specialize the traversal function to do something
when it hits particular higher-level data structures.
README'', CCFS will actually create or read
a file called ``readme''. Though there are 9 different
NFS RPCs taking file names in their arguments, the file names are
always embedded in diropargs3 structures. Thus, we
traverse arguments and manipulate the diropargs3
structures as follows:
/* Define some new type for this particular operation. We could put
* some fields in this structure if we needed to maintain state while
* traversing one set of arguments. In this case, however, the
* operation is simple so we define an empty structure.
*/
struct lcname_t {
};
/* For convenience (since the structure has no state), define a global
* object of type lcname_t
*/
lcname_t lcname;
/* Declare empty default functions for this traversal (for most data
* types we don't want to do anything).
*/
DUMBTRAVERSE (lcname_t)
/* Now overload what the RPC traversal function should do for objects
* of type diropargs3. Note that the argument lcn is just to specify
* what type of traversal this function is part of. We don't even
* need to access lcn, because it has no useful state.
*
* Recall that C++ allows function overloading. Thus, we can define
* multiple functions called rpc_traverse, as long as their arguments
* are of different types.
*/
bool
rpc_traverse (lcname_t &lcn, diropargs3 &arg)
{
arg.name = make_name_lower_case (arg.name);
return true;
}
/* Here is the new dispatch routine. Before relaying the NFS call, we
* transform all file names in the argument to lower-case. The first
* argument to the template is lcname, of type lcname_t. Thus, any
* diropargs3 structures found during the traversal will get run
* through the rpc_traverse function we defined.
*/
void
dispatch (nfscall *nc)
{
nfs3_traverse_arg (lcname, nc->proc (), nc->getvoidarg ()); // <- NEW
c->call (nc->proc (), nc->getvoidarg (), nc->getvoidres (),
wrap (reply, nc));
}
void nfs3_getattrinfo (attrvec *avp, u_int32_t proc, void
*argp, void *resp);
There is one particularly common case of needing to traverse NFS data
structures, and that is to get the attributes from a return structure.
Some calls have multiple attributes--for directories and files. Some
return both pre-operation attributes and post-operation attributes.
nfs3_getattrinfo groups attributes along with file
handles, and groups pre-operation attributes along with the
corresponding post-operation attributes. It returns in
avp a vector of attrinfo structures, defined
as follows:
As an example, the following code prints the before and after sizes of
regular files that are modified, if the RPC reply contains both pre-op
and post-op attributes (these are optional, so the server might send
only one or neither back):
struct attrinfo {
nfs_fh3 *fh;
fattr3 *fattr;
wcc_attr *wattr;
wcc_data *wdata;
};
typedef vec<attrinfo> attrvec;
static void
reply (nfscall *nc, clnt_stat stat)
{
if (stat) {
warn << "NFS server: " << stat << "\n";
nc->reject (SYSTEM_ERR);
return;
}
attrvec av;
nfs3_getattrinfo (&av, nc->proc (), nc->getvoidarg (), nc->getvoidres ());
for (attrinfo *ap = av.base (); ap < av.lim (); ap++)
if (ap->fattr && ap->fattr->type == NF3REG) // Regular files only
if (ap->wattr)
warn << "size: " << ap->wattr->size << " -> "
<< ap->fattr->size << "\n";
nc->reply (nc->getvoidres ());
}
The structures pointed to by fattr and wattr
are part of the reply structure. Thus, you can modify them to modify
the reply you send back to an NFS client. Also, keep in mind that
fattr or wattr or both might be NULL.
Sometimes, you might want to make wattr NULL in the
reply, even if it wasn't that way--an example might be if you need to
know the file type to fix wattr, and fattr
is NULL. You can clear the pre-op attributes in a reply with
ap->wdata->before.set_present (false). For example:
attrvec av;
nfs3_getattrinfo (&av, nc->proc (), nc->getvoidarg (), nc->getvoidres ());
for (attrinfo *ap = av.base (); ap < av.lim (); ap++)
if (ap->fattr && ap->wattr)
fix_wattr_given_fattr (ap->wattr, ap->fattr);
else if (ap->wattr)
ap->wdata->before.set_present (false);
Cryptographic functions
To access these functions, you will want the following include files
in your program:
#include "crypt.h"
#include "aes.h"
The libraries you are using contain a cryptographic pseudo-random
number generator, in a global object called rnd. Before
using the random number generator, you must initialize it.
void random_init ();
void random_init_file (str path);
These functions initialize the random number generator from a bunch of
sources using the current state of the machine you are on.
random_init_file additionally uses a random seed file,
which accumulates entropy from various runs of your program.
path is the path of the random seed file. If
path begins with "~/", it will substitute the current
user's home directory, e.g. random_init_file
("~/.ccfs_random_seed");.
void rnd.getbytes (void *buf, size_t len);
Writes len pseudo-random bytes to memory at location
buf.
u_int32_t rnd.getword ();
u_int64_t rnd.gethyper ();
These functions return a single pseudo-random 32- or 64-bit integer,
respectively.
aes
with the following methods:
The SHA-1
hash function hashes an arbitrary-length input (up to 2^64 bytes) to a
20-byte output. SHA-1 is known as a cryptographic hash function.
While nothing has been formally proven about the function, it is
generally assumed that SHA-1 is one-way and collision-resistant.
These properties are defined as follows:
void setkey (const void *key, u_int len);
This sets the secret encryption key for AES to use when encrypting and
decrypting blocks of 16 bytes. The key must be 16, 24, or 32
bytes. Thus, you cannot directly use a user-supplied password, but
must pad it with 0 bytes to the appropriate length. (Alternatively,
if you want to get fancy, you can hash the user's password to a fixed
length with a cryptographic hash function; this is not necessary for
the lab, however.)
void encipher_bytes (void *buf, const void *ibuf);
encipher_bytes transforms 16 bytes of plaintext data at
ibuf into 16 bytes of ciphertext data which it writes to
buf. It uses the secret key previously passed to the
setkey function.
void decipher_bytes (void *buf, const void *ibuf);
decipher_bytes decrypts 16 bytes, inverting the
encipher_bytes function.
void encipher_bytes (void *buf);
void decipher_bytes (void *buf);
When these functions are called with a single argument, the data is
encrypted or decrypted in place, overwriting the old contents of
memory. (This is the same as calling the two argument versions with
both arguments set to the same pointer.)
The libraries you are using contain an implementation of SHA-1. The
following functions are available for computing SHA-1:
These functions are implemented in terms of a class called
void sha1_hash (void *digest, const void *buf, size_t len);
Hashes len bytes of data at buf.
digest points to 20 bytes of space for the result.
template<class T> bool sha1_hashxdr (void *digest, const T &t);
Produces a hash value for an
arbitrary RPC data structure you have defined in a .x
file. digest points to 20 bytes of space for the
result. If the function fails to marshal t, it returns
false and does not produce an output value.
sha1ctx, with the following methods:
void update (const void *data, size_t len);
Adds len bytes at data to the input being
hashed, but does not produce a result. Thus, one can hash a large
amount of data without having it all in memory, by calling
update on one chunk at a time.
void final (void *digest);
Produces the final result.
digest points to 20 bytes of space for the result.
void reset ();
This must be called if you want to
use a sha1ctx object to computer another hash. (It is an
error to call any method besides reset after
final.)